Table of Contents
This chapter retains something of the introductory spirit of the previous one by providing an overview of the fundamental principles and technologies behind TAN. The overall goal of this chapter is to document the definitions, assumptions, and other matters that have shaped the design of the format. Although this chapter assumes on your part no prior knowledge of any particular technology, it is also not meant to be a tutorial. Links to further reading will take you to more adequate introductory material.
The Text Alignment Network is a modular suite of XML encoding formats. Each TAN format is designed for a specific type of textual data, divided into three classes: transcriptions (class 1), annotations of transcriptions (class 2), and everything else (class 3).
Class 1, representations of textual objects,
consists solely of transcription files. Each transcription file contains the text of
a single work from a single text-bearing object, whether physical or digital (an
object we sometimes term scriptum). There are two types of
transcription file: a standard generic format and a TEI extension. Both are TEI
conformable. These two types are differentiated by the root element, <TAN-T> and <TEI>
respectively. In the future, class 1 may expand to include formats intended to
segment (and therefore align) visual, audio, or audiovisual files; it may also expand
to include a customized form of HTML.
Class 2, annotations of class 1 files, encode
data concerning alignment, lexico-morphology, and other textual claims. There are two
types of alignment, one for broad, general alignments and another for granular,
word-for-word aligments. The former, with <TAN-A-div> as the root element, aligns any number (one or
more) of class 1 files, and permits assorted claims about those files. The latter,
<TAN-A-tok>, aligns
only pairs of class 1 files. Lexico-morphology files, <TAN-LM>, are used to encode the
lexical and morphological (or part of speech) forms of individual words in a single
class 1 file. In the future, class 2 may expand to include syntax
(treebanking).
Class 3, covers everything else. <TAN-mor> declares the
grammatical categories or features of a given language and stipulates rules for
tagging words. <TAN-key>
collects and defines terms frequently used in other TAN files. <TAN-c> supports assertions (in a
syntax inspired by RDF) to provide context to other TAN files. Class 3 may expand in
the future to include transliteration, lexicography, and syntax.
Inclusions: Any TAN file may include any other TAN file, no matter the class of either the including or the included files. Inclusions in TAN behave differently than other kinds of inclusions in markup languages. For example, in XSLT, if file A includes file B, all of B's first-tier children are copied into the root element of A before A is processed. In XML Inclusions, inclusion pertains either to the entire file or to a specific element, named through XPointer. For these reasons, mutual inclusion is not allowed because of its inherent circularity.
In TAN, inclusion is a two-step process. First the included file B is declared by
means of an <inclusion> in
the <head> of document A. Second,
certain elements in document A may include an @include, specifying that the host element should be
replaced by all elements of the same name found in document B. Because of this
behavior, the prohibition on circular inclusion pertains only to select element
names. That is, A and B may validly invoke each other as inclusions, or share
inclusions, as long as there is no circularity in the elements that are
included.
TAN files that refer to or are referred to by other TAN files form a kind of network. Alignment files become the principal point of connection. Below is an illustration of how an ecosystem of independently curated TAN files might interrelate, with arrows showing lines of dependency.
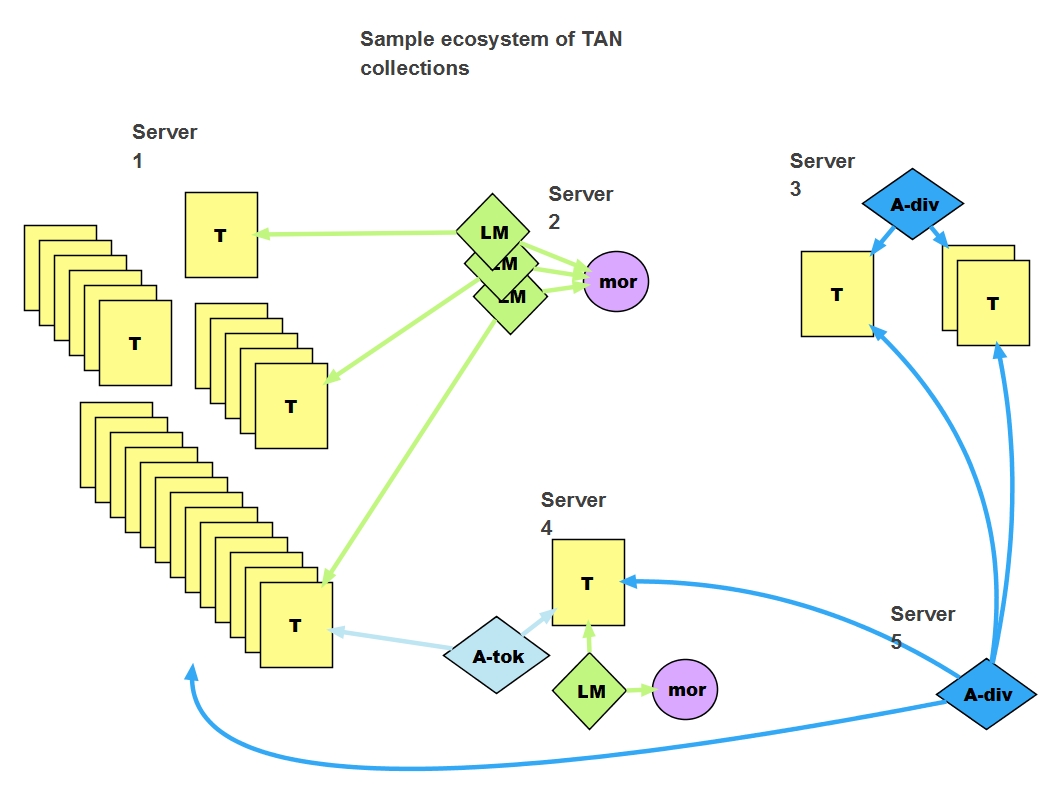
In this hypothetical example, Editor 1 has transcriptions of four different high medieval works and she wants simply to make them available to anyone who want to use them, and posts them on Server 1. Editor 2 (= Server 2), interested primarily in Old French morphology, finds three versions in Server 1 that are in that language and publishes a morphological analysis of them. Editor 3 has provided a small collection of two early interrelated medieval Latin works. Editor 4 has found an Old English version missing from Editor 1's collection, and has decided to provide not only a word-for-word correspondence between it and a key Old French version, but to create a morphological analysis of that Old English version, as a counterpart to Editor 2's work on the Old French version. (He is interested in computing the morphological differences between the Old French and Old English versions.) Editor 5 is interested primarily in showing where Server 1's collection quotes from the works on Server 3, and so merely puts together an alignment of quotations.
This approach adopts what is sometimes called stand-off annotation (or stand-off markup), in contrast to in-line annotation, in which a transcription and its alignments, morphology, and other annotations are placed in a single file. (Most TEI and HTML files rely upon in-line annotation.) In the TAN format, stand-off annotation has been extended into a modular design, with each module designed to to be simple and complement the other modules. (In fact, the combined sum of elements and attributes from TAN modules are roughly equivalent to the number of elements in HTML.) Modular stand-off annotation has been adopted for several reasons:
An editor can work on a file with minimal distraction, focusing on a limited set of closely related questions. (Editors 2 and 5 can work off the same master files provided by Server 1, even though they have very different research interests.)
Complementary or competing annotations can be made, even if those annotations overlap (a major problem for in-line annotation, where according to XML rules no element may interlock or overlap with another). (Editor 5 may choose to incorporate or ignore the alignments that Editor 3 has made of her collection.)
Annotations can be made concurrent to any others that may already exist, allowing for rich and complex analyses.
After a TAN collection is published, any other TAN files that it refers to, or any TAN files referring to it, can be aggregated into much larger and more complex datasets, which can then be queried to answer questions that might not have been anticipated.
Editorial labor can be conducted without central coordination, as individuals work at their own pace, independently, on separate files.
When errors are found, they can be corrected in master files. Anyone depending upon that master file as a source will be notified of changes that have been made and they can deal with them accordingly. (Editor 1 can post typographical corrections, and if she logs the change with a time-date stamp, anyone using the file, upon validating their files, will be sent information or a warning about the change. Similarly, Editors 2 and 4 can let Editor 1 know about their work, and Editor 1 can update the Old French versions with cross-references.)
Any data file can be released, circulated, and used independent of any other that points to it, or to which it points.
Connected files can be combined and transformed in any number of ways to produce a wide variety of derivative documents (e.g., collated versions, statistical analysis). A transformation created for one set of TAN documents will work identically on other TAN documents of the same format. (If someone creates a tool to synthesize a transcription and an associated TAN-LM file, it can be applied to both Editor 2's and Editor 4's work.)
The TAN family of formats can be expanded to allow other types of linguistic data, and therefore other lines of research.
Stand-off annotation is not without its liabilities. Files might be altered or altogether deleted, rendering dependent files meaningless. An editor may find that not having the annotated text in the same place as the annotation is an inconvenience. These are significant challenges, but TAN validation rules have been designed to mitigate them somewhat.