Table of Contents
TAN files are suited for dozens of types of applications. A few have been developed
and successfully tested on select projects. The most mature of these have been provided
in the subdirectories applications and utilities.
Utilities are designed to assist in import, export, creating, and editing TAN files. They tend to support straightforward tasks, and the code is relatively stable.
Applications, on the other hand, support study and research. Most of these take a set of TAN files, process them, and create interactive, dynamic HTML files that let you study and analyze textual features and relationships. Applications can have quite complicated code bases, and tend to have features that are not fully supported, or are in the planning phase.
TAN utilites and applications are written in XSLT. XSLT, which stands for XSL Transformations, version 3.0,[22] is very powerful, and has a distinctive syntax and design. Many people do not know how even to begin to use it. Even some seasoned programmers approaching XSLT for the first time can find it baffling or impenetrable. An XSLT application is rather different from others that may be more familiar to you.
This chapter begins with a basic orientation to XSLT. You may not be ready to write anything in XSLT, but you can begin to read and understand an XSLT file. We then look at how to run an XSLT application, and then look at the standard TAN utilities and applications.
In most computer applications, the expected rules are rather straightforward. Given zero or more inputs, zero or more outputs are returned. Many times the application is driven by a graphical user interface (GUI), to allow the user to configure the application.
XSLT applications do not have a GUI. They also have a somewhat different approach to input and output. In the classic approach to XSLT, the input consists of an XSLT stylesheet and an XML file, passed to a processor. But there is opportunity for secondary input. And classically there is one output, but XSLT provides the opportunity to create secondary outputs. The basic model is depicted here:[23]
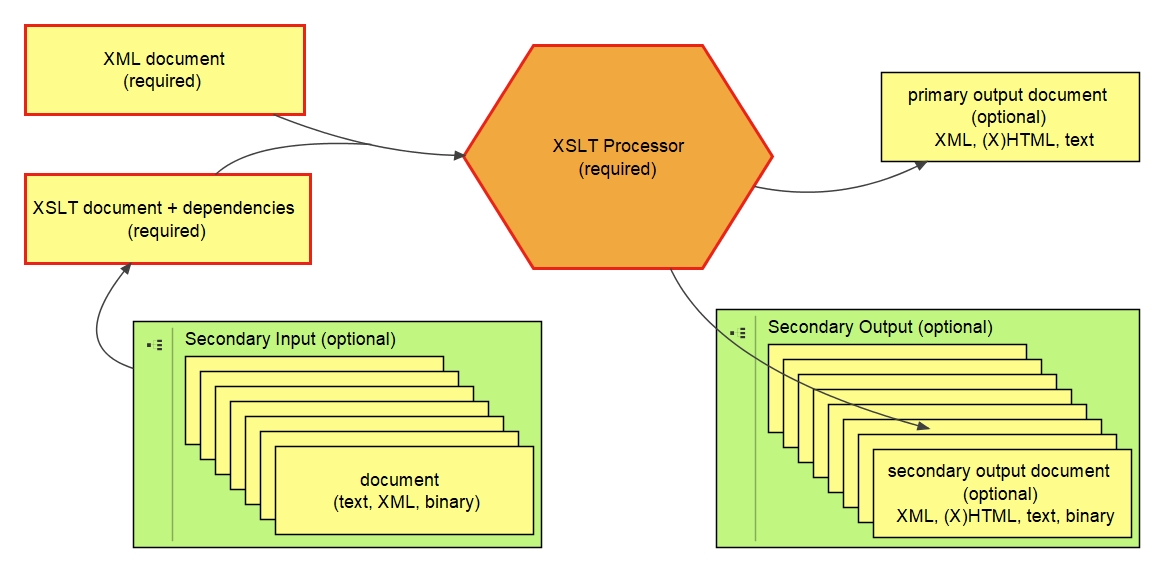
In the classic XSLT process, there are three key requirements:
an XML file, to catalyze the process;
a master XSLT file, to declare the rules that should be followed;
an XSLT processor.
The process begins, actually, with the processor, which is normally given URLs that specify where to find the input, the stylesheet, and where to place the output. The processor fetches the XSLT stylesheet, and looks for any associated components. After compiling the master stylesheet and its dependencies, the rules are applied to the catalyzing XML file. Along the way, the processor may fetch secondary input documents, if the XSLT file so instructs.
After all the rules have been applied, the processor saves the primary result document—if there is one—to the specified target URL. If the XSLT rules tate that secondary result documents should be saved at certain locations, the processor does so.
Therefore, in any XSLT operation, there are really two possible types of input and two types of output. We use the terms primary input for the catalyzing XML file and secondary input for input that is added during the process. We use the term primary output for the main result tree and secondary output for any other output created along the way. The terms primary and secondary refer only to their position in the process, not their importance to the application. Indeed, there are XSLT applications where the secondary input and secondary output are far more important than the catalyzing input or primary output. Sometimes the primary input does not matter at all, and sometimes there is no primary output.
You will normally have direct control over the primary input, because you will need to select an XML file to catalyze the process. But any control you might exercise over the secondary input could be hidden. The application might derive secondary input based upon your primary input, or it might provide parameters, to allow you to control the secondary input.
Likewise, you normally have full control over where the primary output should go. But you may not have that kind of control over the secondary output. You may or may not have control over that.
When you get an XSLT file, try to understand first of all what kinds of input is expected, and what types of output are returned, and where. In general, if there is not good documentation and the XSLT does not come from a trusted source, do not try to run it.
XSLT is itself an XML document, and can be treated in every way as an XML document. If there is something you can do to an XML document, you can do it to an XSLT file too.
The XML syntax makes the code somewhat more verbose than the syntax of other languages. Many of the instructions are placed in elements, which frequently have opening and closing tags. Unless otherwise specified, white space is flexible, and the document can be reformatted and indented as one likes. Most XSLT files are indented, but in most cases that indentation can be changed or removed without affecting the output.
XML in general uses namespaces, to allow mixed vocabularies. So too, XSLT
files can interleave elements from different namespaces. In general, most XSLT
files do not define a default namespace: that is up to the designer to do. All the
XSLT elements are in the namespace http://www.w3.org/1999/XSL/Transform, and bound to the
prefix xsl.
Because an XSLT file is itself XML, then it can be designed to be the primary input of an XSLT process, even its own. Running an XSLT file against itself can be useful in cases where the primary input is irrelevant.
An XSLT file may invoke other XSLT files, or be invoked by them, through the
<xsl:import> and <xsl:include> instructions.
Inclusions and imports are recursive: the processor looks not just for the ones it
imports/includes, but the ones they import/include, and so forth.
The modular approach to XSLT allows developers to be more efficient and
effective when writing code. Routines that serve one process well can serve
another. But it also means that when you first open up an XSLT file, you do not
understand what it does until you trace the chain of <xsl:import>
and <xsl:include> instructions, and find all the stylesheets it
depends.
That process can be cumbersome, but straight-forward. More challenging is asking yourself whether the file you began with is a master stylesheet (the intended starting point for a process), or if it is itself a dependency. You may not be able to tell, without documentation. Tracing these lines of dependence is important, because you need to find the appropriate starting point, and understand how it relates to the network of XSLT files.
In most programming languages, you write a list of things for the computer to do, in a specified order, governed by conditional branching. This list-like approach to programming is called imperative programming.
XSLT has imperative components, but at its heart, it is a declarative programming language. That is, an XSLT programmer writes not a list of steps to be followed but rather a set of rules or principles that should be observed. It is up to the processor to determine the most efficient path to honor those rules or principles.
Imperative and declarative programming can be compared to real-world examples. Suppose you have a pile of candies that need to be sorted. Imperative programming is like telling a child: get one candy; if it is like such-and-such, put it here; repeat. Declarative programming is like telling that same child, I do not care how you do it, but make sure that the final groups look like such-and-such.
If you are familiar with Cascading Style Sheets (CSS) you might appreciate better how the XSLT programmer approaches a task. In CSS, styling instructions are provided by selector patterns that match certain elements within the HTML file. CSS instructions can frequently be placed in different groups and orders, and with different levels of specificity, to infer priority. It is up to the browser to take those rules and find the most efficient way to apply the styles. Such a declarative approach allows the writer of CSS to efficiently write, edit, and maintain some rather complex code.
Because of its declarative approach, the order of an XSLT's root element children is flexible. Most often, order does not matter. The children of the root element, called declarations, are special, because they stipulate the rules or principles that should be followed. All of the declarations of the stylesheet's modules are also taken into consideration. Which means that when you are reading a particular section of an XSLT file, you might think you understand what is being done. But there may be declarations in other parts of the file or its inclusions/imports that affect whether the particular component you are looking at is called, or in what priority.
As a general rule of thumb, when you read an XSLT file to understand what it does, do not put much importance on the order of its declarations. They will not be followed in that order. There are cases where order is important, but coming freshly to an XSLT file, try to get a bird's-eye overview of all the components. Look at all the declarations, wherever they are found. As you read, don't look for the application's steps. Try to understand the intended outcome.
In most programming languages, you can write something like the following pseudocode...
x = 1 x = x - 1 return x
...and expect the output 0. The variable x starts with the value 1, but then changes, because variables are mutable.
In XSLT, variables and parameters are immutable. You cannot change the value
of a variable or parameter. A variable can be destroyed (and along with it, its
value), and then a new instatiation of the variable can be created, but once
again, within its life (scope), it does not change. If you see two
<xsl:param> or two <xsl:variable> instructions
that create variables with the same name, they are in different scopes (or the
XSLT is invalid).
Both variables and parameters might be in a namespace. If there is a colon in the name, the variable or parameter is bound to a particular namespace. Check the prefix to see its namespace.
As a user of an XSLT stylesheet, you should not worry too much about any XSLT variables. Certainly, you can change them if you want, but at that point you are stepping into the role of developer. We assume here you are interested primarily in using, not altering, an XSLT application. Your should focus, instead, upon parameters, but only a certain kind: global, relevant parameters.
Global parameters are found exclusively as children of a root element. That is, they are declarations (see previous section). Any parameters that are more deeply nested are local parameters, and you shouldn't change them.
Not all global parameters are relevant. If you have a master stylesheet that includes another one, that stylesheet may have global parameters that are designed to accommodate some other including XSLT application. Normally, you will know which global parameters are relevant for your purposes only by studying the file's documentation, or its code.
Every global parameter is a developer's invitation to the user to configure the XSLT application. Some parameters exercise an enormous influence over the type of output; others have no effect whatsoever; yet others might cause the application to crash if you put in the wrong value. Before you try to change a parameter, you should understand something about data types. See the section called “Configuring global parameters”.
XSLT relies upon a sublanguage called XPath, which is itself a proper subset
of another powerful XML programming language, XQuery. You will most commonly read
or use XPath expressions in the context of the @select attribute in
various XSLT instruction elements.
XPath is an enormous topic, and well worth learning. Because this chapter is geared to helping new users quickly get comfortable with using and configuring an XSLT application, we introduce here some very common, useful XPath expressions. They are presented according to four basic concepts: navigation, filter expressions (predicates), operators, and functions.
Every XML file is a tree, and at the heart of XPath is a language for traversing that tree. XPath gets its name, because it was designed to provide a path from one point to many. An XPath expression always assumes some kind starting point for the path. That starting point is called the context, which is commonly a node inside an XML tree.
Because this short guide is aimed at users who are configuring global parameters, we will assume in our examples here that the context is the primary input XML document. That means that the context is the document node of the primary input.
When an XPath expression begins with a single slash, the document node is
selected. The following example shows how to bind to the global parameter
$doc-a the document node of the primary input.
<xsl:param name="doc-a" as="document-node()" select="/"/>
Once you start an XPath expression, you add to it by adding new
components. This builds the path of traversal. Commonly you want to traverses
downward through the tree, toward the leaves. You do this most frequently by
element name. If it is in a namespace, you either need to start with the
appropriate prefix, or else use an asterisk (represents any prefix), followed
by a colon. The following example selects the <tei:TEI> root
element of the primary input XML document. If the root element is not named TEI
and it is not in the namespace bound to the prefix tei, then you
will get an error, because this global parameter expects exactly one item, no
more, no less.
<xsl:param name="tei-root-element" as="element()" select="tei:TEI"/>
The previous example would have worked as well with
/tei:TEI, which says, in effect, go to the document node, then go
to the element TEI. We have left it off because we are assuming that the
document node of the primary input document is the context (i.e., the assumed
starting point for an XPath expression). Another XPath expression comparable to
the example above would be *:TEI, which selects the root element
if its name is TEI, regardless of what namespace it is in.
The nested elements of the tree can be traversed by separating element names with the slash. The following example navigates from the document node leafward to the TEI's body, three levels deep. This example also shows how to use the asterisk alone, which stands for any element.
<xsl:param name="tei-text" as="element()?" select="tei:TEI/*/tei:body"/>
If you want to go deeply into the document, and select a variety of elements, you can do so with the double-slash operator, which navigates down to all descendants.
<xsl:param name="tei-abs" as="element()*" select="tei:TEI//tei:ab"/>
The example above selects every <ab> in a TEI document.
If one <ab> nests inside another, both are picked.
To select an attribute, use the @ sign. In the following
example the XPath expression points to an attribute that is bound to a
namespace via the prefix xml. One commonly finds
@xml:id, @xml:lang, @xml:space, but
most of the attributes you encounter will not have namespaces, even if their
parent elements have them.
<xsl:param name="tan-t-lang" as="attibute()" select="tan:TAN-T/tan:body/@xml:lang"/>
To select any attribute, use @*. The following example
selects all the attributes in <change> elements in a TAN file.
Note the use of the asterisk for the root element. This expression will work no
matter which TAN format is used.
<xsl:param name="change-attrs" as="attribute()+" select="*/tan:head//tan:change/@*"/>
You can use parentheses and commas to group and add nodes. In this
example, the XPath expression points to the TAN <body>, then
selects all the children comment nodes, text nodes, and elements.
<xsl:param name="interesting-nodes" as="item()*" select="*/tan:body/(text(), comment(), *)"/>
There is a slightly simpler way to do the preceding example, and it also finds any processing instructions:
<xsl:param name="interesting-nodes" as="item()*" select="*/tan:body/node()"/>
In an XPath expression node() finds everything except
attributes and namespaces.
There is much, much more about XPath navigation, but the samples above should get you started. See XPath 3.1 for comprehensive, technical coverage.
An XPath expression that traverses a tree might return more nodes than you want. You can reduce what is captured by applying a predicate, which is an XPath expression that filters results. A predicate consists of an XPath expression enclosed by two square brackets, inserted in the middle of, or at the end of, another XPath expression. The predicate must be placed in an XPath expression immediately to the right of the step you want to filter. For every context node found, the predicate will be evaluated as a boolean. If the predicate is true, the node is retained, otherwise it is discarded.
A very simple example shows how to pick the second <div> in the body of a TAN-T file:
<xsl:param name="second-div" as="element()?" select="tan:TAN-T/tan:body/tan:div[2]"/>
This predicate, [2], returns true if a given node is the
second child <div> of <body>. The simple
numeral 2 in the filter expression is actually shorthand for a
slightly longer expression based on XPath functions (discussed below),
[position() eq 2].
The next example finds every <div> that has an attribute
of @xml:lang.
<xsl:param name="second-div" as="element()*" select="tan:TAN-T/tan:body//tan:div[@xml:lang]"/>
This predicate, too is shorthand for [exists(@xml:lang)],
another XPath function.
Predicates may nest. Any nesting predicate still takes as its context the
step immediately to the left. This example finds every TEI
<div> tag, but only if it has a <p> that
has a <quote>.
<xsl:param name="divs-with-quoting-ps" as="element()*"
select="tei:TEI/tei:text/tei:body//tei:div[tei:p[tei:quote]]"/>Predicates may chain, simply by appending predicates. The following example reduces the previous example to the first instance.
<xsl:param name="divs-with-quoting-ps" as="element()*"
select="tei:TEI/tei:text/tei:body//tei:div[tei:p[tei:quote]][1]"/>The position of chained predicates is important. Whereas the preceding
example filtered the <div>s then picked the first one, the next
example finds the first <div> (one that does not have a
preceding sibling <div>), and retains it only if it has a
<p> with a <quote>.
<xsl:param name="divs-with-quoting-ps" as="element()*"
select="tei:TEI/tei:text/tei:body//tei:div[1][tei:p[tei:quote]]"/>The previous two examples look very similar, but they produce very different results.
Predicates may be placed anywhere in an XPath expression. The following
gets all top-level <div>s only if the root element has an
@TAN-version, a distinctive marker of all TAN files.
<xsl:param name="top-level-divs" as="element()*"
select="*[@TAN-version]/*/*:body/*:div"/>We have already seen some basic XPath operator expressions, namely, in
the comma and the parentheses. XPath has many more operator expressions, some
of which should be immediately recognizable: + for addition,
- for subtraction, * for multiplication, and
div for division. (The slash is not used for division, to avoid
clashes with the step separator.) The keyword to, with an integer
on either side (the smaller on the left), creates a range, e.g., (1 to
10).
XPath also has comparison expressions. Although < and
> can be used for "less than" and "greater than", those symbols
interfere with XML syntax. Instead, use the expressions lt and
gt. The expressions le and ge can
also be used, to mean less than or equal to, and greater than or equal to,
respectively.
For checking equality, you will most often use the =
expression. There is also eq, but this can be used only to compare
exactly two items. The = is very powerful, because it will return
true if there is any item in the sequence on the left hand side that is equal
to any item in the sequence on the right. Consider for example, an XPath
statement that compares two sequences, each with two integers: (1, 2) =
(2, 3). The statement is true because there is at least one pair of
equal items. Because the expression = is used so frequently to
compare sequences, you might think of it as meaning "overlaps with."
Complex expressions can be combined with and,
or, and grouped with parentheses, as needed.
As you work with XSLT global parameters, you will find that most operator
expressions are used within the filtering predicates. The following finds all
<div>s with an attribute @type whose value is
"chapter".
<xsl:param name="chapter-divs" as="element()*" select="//*:div[@type = 'chapter']"/>
This expression finds the top-level divs in 2nd, 3rd, 4th, and 8th place:
<xsl:param name="some-divs" as="element()*" select="//*:body/*:div[position() = (2 to 4, 8)]"/>
The following example returns any <div> whose values of
@n and @type match.
<xsl:param name="dupl-n-and-type-divs" as="element()*" select="//*:div[@type = @n]"/>
XPath expressions become enormously powerful when combined with the
language's 155 standard functions. You have already seen two of them,
position() and exists(). In a brief survey like
this, it is possible to illustrate only a few of the most common standard
functions you are likely to use when configuring the global parameters of an
XSLT application.
last(): returns an integer representing
the size of the context. The following examples contain an implicit
position() eq, just the same as the filter expression example
above, with [2].
<xsl:param name="last-div" as="element()?" select="//*:body/*:div[last()]"/>
<xsl:param name="penultimate-div" as="element()?" select="//*:body/*:div[last() - 1]"/>count(): returns the number of items in
a sequence. The following returns all TAN-T <div>s that have
more than three children <div>s.
<xsl:param name="populous-divs" as="element()*" select="//tan:div[count(tan:div) gt 3]"/>
not(): returns true if the expression it contains is false, or false if it is true. This function is very widely used, to great effect. The first example belowe finds all leaf divs, and the second, all leaf elements:
<xsl:param name="leaf-divs" as="element()*" select="//*:div[not(*:div)]"/>
<xsl:param name="leaf-elements" as="element()*" select="//*[not(*)]"/>Whereas the = operator is very popular, its counterpart,
!=, is not used very much, because its results tend to be
uninteresting. The true complement of = comes with
not(), as illustrated in this example, which retrieves all
<div>s that are not of a certain type:
<xsl:param name="certain-divs" as="element()*"
select="//*:div[not(@type = ('ep', 'title', 'pref'))]"/>
lower-case() / upper-case(): converts a string to all lowercase / uppercase values. This example looks for any text node that has a certain value, but only after it has been rendered lowercase.
<xsl:param name="some-elements" as="text()*" select="//text()[lower-case(.) = 'a b c']"/>
Note the use of the period, which is shorthand for the context item.
normalize-space(): takes a string, removing all space from the beginning and end, and replacing any consecutive block of intermediary space with a single space. This function is very useful when you wish to compare texts that may be indented. The preceding example might have missed some text nodes that had initial or trailing space. It can be adjusted as follows:
<xsl:param name="some-elements" as="text()*"
select="//text()[normalize-space(lower-case(.)) = 'a b c']"/>Many times XPath functions must call each other. You may nest them, as in
the example above, or you may use pointing syntax, =>. Use the
syntax you are most comfortable with.
<xsl:param name="some-elements" as="text()*"
select="//text()[(lower-case(.) => normalize-space()) = 'a b c']"/>contains() / starts-with() / ends-with(): tests to see if the string in the first parameter contains / starts with / ends with the string in the second. The following finds all elements that contain the text "straw":
<xsl:param name="some-elements" as="element()*" select="//*[contains(., 'straw')]"/>
contains-token(): tests to see if the
string in the first parameter has as one of its "words" the string in the
second, based on segmenting the first string at blocks of space. The preceding
example would have picked up "strawberry"; in the next example, using
contains-token(), "strawberry" would not be selected:
<xsl:param name="some-elements" as="element()*" select="//*[contains-token(., 'straw')]"/>
matches(): tests to see if the string in the first parameter matches the second, which is a regular expression. Several TAN applications rely heavily upon regular expressions, which provide very powerful way of finding and replacing text. See the section called “Regular expressions”. The following example finds any text node with one of the seven weekday names in English:
<xsl:param name="text-nodes-with-weekdays" as="text()*"
select="//text()[matches(., '(Sun|Mon|Tue|Wednes|Thurs|Fri|Satur)day')]"/>There are, of course, many, many more XPath functions. For the complete list, along with all the specifications, see XPath Functions and Operators 3.1.
[22] XSL, which stands for Extensible Stylesheet Language, was the predecessor language.
[23] The classic view presented here does not take into account another way of configuring an XSLT application, where a particular starting point is designated, the initial template. In those cases, primary input is unnecessary.