Table of Contents
This chapter addresses anyone who wants to develop their own applications using TAN. Some may want to experiment, revise, or extend the code that already exists. Others may be developing their own XQuery or XSLT application, and intend to use select TAN functions. Yet others may want to customize the standard TAN applications or utilities, perhaps as part of a pipeline or workflow, or for populating a website.
TAN is very developer-friendly. The function library is one of the richest, largest of its kind. If you are accustomed to doing natural language processing through the Natural Language Toolkit, Classical Language Toolkit, or a comparable package, you may find that TAN has the building blocks you need to do the same activities within an XSLT or XQuery environment.
All TAN digital assets are organized primarily by role. At the heart of TAN is its function library. This library is the foundation for the schemas that validate TAN files, as well as applications and utilities. All of those resources contribute to a large share of the content in these guidelines.
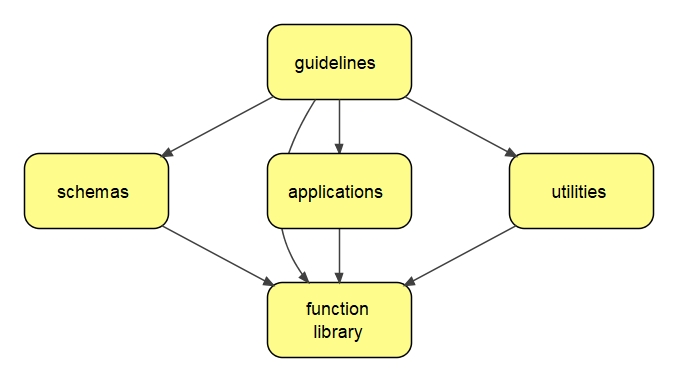
The TAN function library is so named because it relies heavily upon functions. But, because it is written in XSLT, there are also global parameters, global variables, templates, keys, and other declarations. Certain design principles have been adopted when designing and organizing these declarations.
Validation mode. The TAN function library was
designed first and foremost to drive the validation process. That process prioritizes
dispensing with parts of the primary input file no longer needed for error-checking.
As the TAN fuction library grew to supporting utilities and applications, a sharp
distinction needed to be drawn between processing for validation and processing for
other purposes. The static global parameter $tan:validation-mode-on
exerts a significant influence upon many operations. Files in the
functions subdirectory whose names include the keyword
extended are excluded from the package when validation mode is on. By
default validation mode is off, fetching everything in the TAN function
library.
Named templates. In general, functions have been preferred over named templates. This allows TAN operations to be used in XPath expressions, and contributes to more concise code. Named templates have been used only when result documents need to be created, or when tunnel parameters need to be preserved.
Functions. All functions have their visibility
declared public or private. You are welcome to use private functions, but keep in
mind that they are generally specialized. Some functions have parallel cached and
non-cached versions, to support environments where memoized functions are not
allowed. Many functions have multiple versions based on the number of parameters
(arity). Lower-arity functions contain comments that point to the highest-arity
version, which is fully annotated by enclosed comments. We place them inside the
<xsl:function>, so that if a function needs to be copied or moved,
the documentation always accompanies it. Documentation shares a common structure:
first, the intended input; second, the intended output; third, other notes; finally:
kw: with a comma-delimited list of keywords categorizing the
function.
Template modes. Every template mode has an
associated <xsl:mode> declaration, which always defines the default
behavior of the template. To reduce the chance of interference with XSLT applications
that might include the library, there is only one template that defines behavior for
all template modes (mode="#all"), at a very low priority, for elements
that contain validation error messages. That means that you can use
<xsl:include> or <xsl:import> without worrying
about conflicts with template modes in your host application. All mode names are set
in the TAN namespace, to avoid conflicts with dependent resources.
Keys. For convenience, all keys are kept in files
at functions/setup.
Character maps. For convenience, all character
maps are kept in files at functions/setup.
Global parameters. Most global parameters are
invitations to the user to configure the environment, and they are placed in the main
parameters directory. A few global parameters are reserved for
technical processes, and they are kept in files at functions/setup. All
global parameters are bound to the TAN namespace. The exception to this general rule
of thumb are the global parameters unique to specific utilities and applications;
they are placed in no namespace. Doing this has helped solidify the boundaries of the
TAN function library.
Global variables. Development work revealed that global variables, even those that were not used, frequently slowed the validation process. Therefore global variables are kept to a minimum within the standard components, but are used more extensively in the extended components. Each global variable is bound to the TAN namespace. Those whose values rely upon the primary input file are constructed under the assumption that the primary input file is a TAN file.
For more specific explanation of individual components see Chapter 13, TAN functions, templates, global variables, and keys.