TAN Tutorial 1
Preparing a TEI Corpus for the Text Alignment Network
Session 2
Transcriptions
Objectives
- Adjust TEI files to be TAN-compliant.
- Coordinate transcriptions with vocabulary.
- Understand how TAN handles space, Unicode, and word division, and other types of normalization.
- Learn how to handle reference systems.
Transcriptions
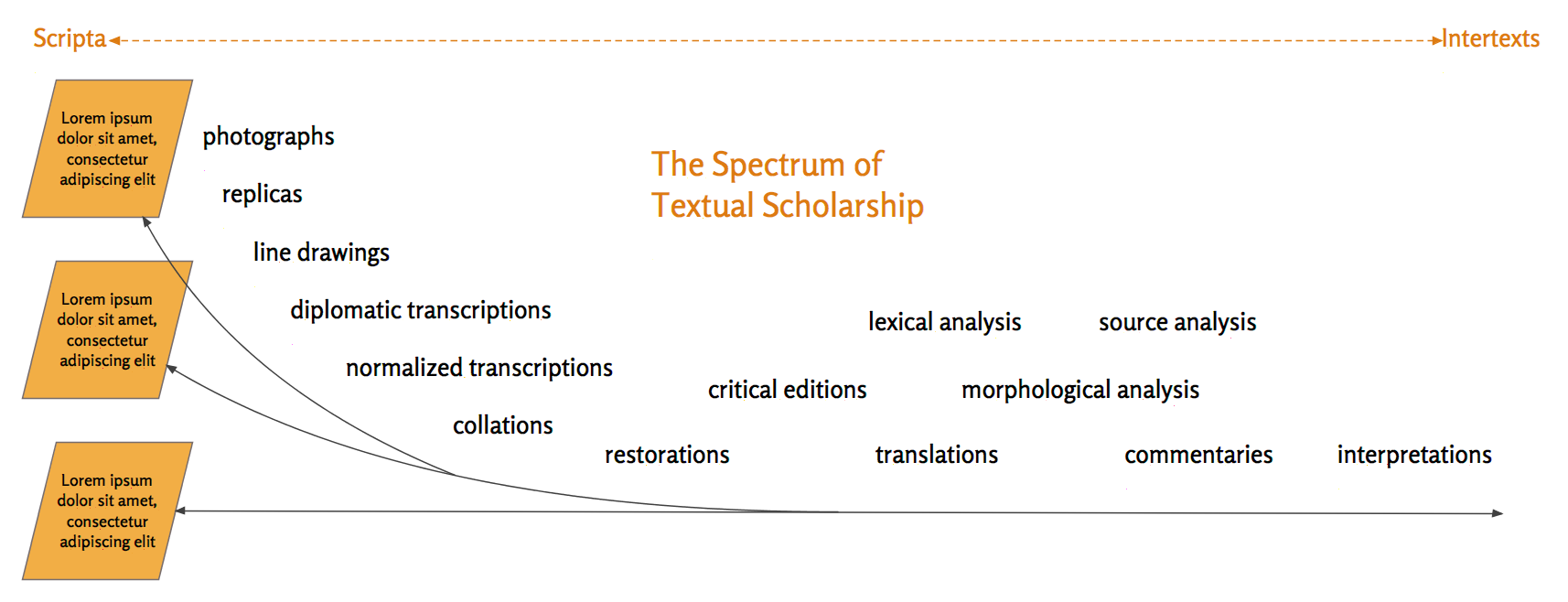
Varieties of TEI
| Sample | Gaze | Comments |
|---|---|---|
| Averroes, Commentum super libro Peryermenias, transl. William of Luna | Mixed | Many invalid structures; inconsistencies |
| Biblioteca Apostolica Vaticana, Vat. Lat. 3827, fol. 74v-75r | Scriptum | More metadata than transcription |
| Decree of Cyrene for the citizenship of the Thereans, Therean 'decree' and founders' oath | Scriptum | Contains bibliography, text, translations, apparatus, commentary |
| Kungliga biblioteket, A 13 | Scriptum | Only manuscript description; no body text |
| Shakespeare, The Phoenix and the Turtle | Intertext | See inline comments |
| Plato, Euthyphro, Burnet translation | Intertext | See inline comments |
Suitability for TAN
- Intertext-orientation
- Normalization
- Individual files restricted to:
- one work
- one version
- one scriptum
- one reference system
Not all TEI files are appropriate for TAN, and that's ok.
TAN Transcriptions
Class 1 files
- First of three classes: transcriptions
- Format: TAN-T or TAN-TEI
- Metadata focused on transcription
- TEI: based on TEI All
- TAN-T: "plain text" TEI
The transcription
- One work, one version, one scriptum, one reference system
- Competing reference systems? Use TEI anchors or TAN
<redivision> - Core structure:
<div>s @typetethered to URIs@npermits synonyms
TAN-ifying TEI
<TEI>
- must have
@idwith tag URN - must have
@TAN-version - takes
<head>, placed between<teiHeader>and<text>, in the TAN namespace,tag:textalign.net,2015:ns; this head is rooted in RDF semantics and focuses exclusively on the transcription
<text>
- No extra strictures, but during Schematron validation (not
RELAX-NG), this element and any children
<front>and<back>will be ignored. Of its children, only<body>will be Schematron validated.
<body>
- must take
@xml:lang - any non-
<div>children will be ignored during Schematron validation - contents must be restricted to a single version of a single work
- all descendant text nodes will be treated as the transcription
<div>
- may encompass a textual division of whatever size you like (like HTML)
- all children elements are either (1) only
<div>s or anchors such as<pb>or (2) non-<div>s - must take
@typeand@n(or only@include) -
@typemay take multiple values, space delimited @nmust match:[\w\._]+([\- ,]+[\w\._]+)*. Allows synonyms, sequences, ranges.
Demonstration
TAN-TEI file (except
head)
Exercise 1
Demonstration
Exercise 2
Normalization
TAN is intertext-oriented, so normalization should be applied
liberally
- Space
- Punctuation
- Ligatures
- Case
- Orthography
- Line breaks
Normalization Enforcement
- Unicode NFC
- Space normalization: every
<div>has an assumed single space unless it ends in a discretionary hyphen or no-break character. - Values of
@n(and full references) should not appear in the text itself. (Use@rendif need be.)
Exercise 3
Reference Systems
Reference systems
- All div types can be classified as material or logical.
- Reference systems always grounded in a particular scriptum, not necessarily the source.
- Multiple reference systems? Create separate files, linked via
<redivision> - Syntax
- hyphen: range || 1-3 = division 1 through division 3 (range)
- comma: "and" (parataxis) || 1, 3 = division 1, then division 3 (sequence not hierarchy)
- period, colon, etc.: levels of hierarchy (hypotaxis) || 1.3 = division 1 subdivision 3 (hierarchy not sequence)
@n basics
- Strings, numerals, or both
- Not case sensitive (ABC = abc)
- Numeration systems supported: Arabic, Roman, letter, Arabic + letter, letter + Arabic
- Ambiguity of Roman vs. letter resolved with
<numerals priority="">(e.g., does "c" mean 3 or 100?) - Simple numeration, e.g.,
n="1"n="i"n="a"n="1a" - Complex numeration, e.g.,
n="1-4"n="2a-2d, 2f" - Non-numeration, e.g.,
n="matt"
@n advanced
- Referring to Biblical books, generic div types (e.g., title, epilogue) has been difficult because everyone uses their own abbreviations.
- TAN
@nsynonymity reconciles divergent practices. - Must be invoked, e.g,
<vocabulary which="bible eng"/> <n-alias div-type="">, optional, is used to enhance performance for synonyms of@n
Exercise 4
Recap
What we've learned
- Adjust TEI files to be TAN-compliant.
- Coordinate transcriptions with vocabulary.
- Understand how TAN handles space, Unicode, and word division, and other types of normalization.
- Learn how to handle reference systems.